
Photo: Christian Englmeier on Unsplash.
6 minute read
Real-time tabulation and perturbation of census results
The Office for National Statistics (ONS) is using Cantabular to generate outputs for the England and Wales Census 2021. What are the key reasons for Cantabular’s existence and how have they been achieved? In this blog post we outline some of the approaches we’ve taken to achieve performance goals in Cantabular and how these have enabled new approaches for Census 2021.
2011: Tested strategy
The ONS developed a disclosure control method for the 2021 Census which built on the techniques used for the 2011 Census where row swapping was the primary means of protection. Row swapping is where individuals and households, most often with similar characteristics, are swapped with those in geographic areas that are nearby. This is done to increase protection against individuals, particularly those with distinctive characteristics.
In 2011 each candidate cross-tabulation was evaluated as to whether it was disclosive across the whole of the population. This is the only feasible approach when checks are done manually. However, disclosiveness varies considerably by geographic area for some combinations of variables. Using the same criteria for all geographic areas means that some data which could be published is not.
2021: New rules
To solve this problem and publish more data the ONS developed a strategy of automated rule checks. However, there is a problem: publishing data for some areas while providing totals for coarser categorisations creates the possibility of differencing to derive the unpublished tables.
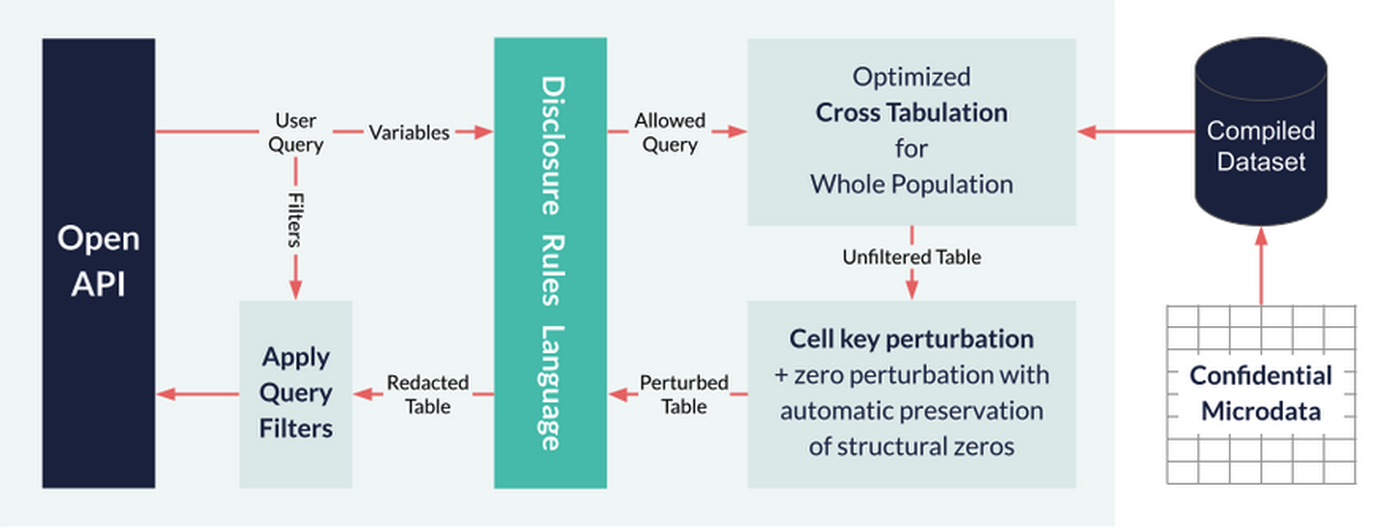
To fix the problem of differencing the ONS turned to the cell-key perturbation method. This applies perturbation to output crosstabs. The ONS chose to keep the cell value changes as minimal as is feasible to provide sufficient protection when combined with the aforementioned row swapping.
The ONS prototyped their approach using statistical software tools. However the result was too slow to be used in an interactive table builder on the web. The ONS engaged The Sensible Code Company (SCC) to build upon our existing software to develop a prototype that was fast enough. This was later developed by SCC into the Cantabular suite.
How fast can you make a table?
Our first step was to develop fast crosstab software. For a crosstab on large datasets we need to read a lot of data, so it is going to be critical that we make reading as fast as possible:
Read only the data you need and nothing else
Store the data compactly to minimise the amount that needs to be read
We need to use a database / on disk file format that facilitates this approach. Cantabular takes the approach of using its own custom file format, but other approaches are possible.
What else can we do on a modern processor to make things faster? Here are a few things we should think about:
branch prediction
memory prefetch
cache line size
SIMD instructions
Cantabular software is designed with these in mind and has been iterated with experiments to continuously improve performance.
Perturbation at speed
Cell-key is a fairly simple algorithm and overlaps somewhat with crosstab because you also need to compute the eponymous key for each cell. Having computed the keys you use them together with the value in the cell to look up the perturbation to be applied. The perturbation step is only a significant contributor to the total time if the size of the output table is large. It is harder to find performance wins here because of the inherently random nature of the memory access. Nevertheless there are some: look how we can improve modulus!
What should we do with nothing?
It is also common with cell-key to provide a method for perturbing zero cells. These cells have no contributing rows from the microdata so have no cell key. The solution is a key associated with each category of a variable: each cell is uniquely identified by a combination of such categories. We pick a certain proportion of the zero cells to perturb and select which ones by ordering the zero cells according to keys. We also need a way to tie-break cells with equal keys and can use the order of the cells in the table to do so.
However there are some zeros we don’t want to perturb: the so-called “structural zeros”. These are “impossible” combinations of categories that are not naturally present in the data such as married infants. We could try to enumerate these combinations, but a better approach is to look for zeros in a sufficiently large section of the population in order to infer them. Cantabular can do this in real time by creating a crosstab at the appropriate level. It is quicker to do this by summing up rather than re-tabulating.
Tabular governance
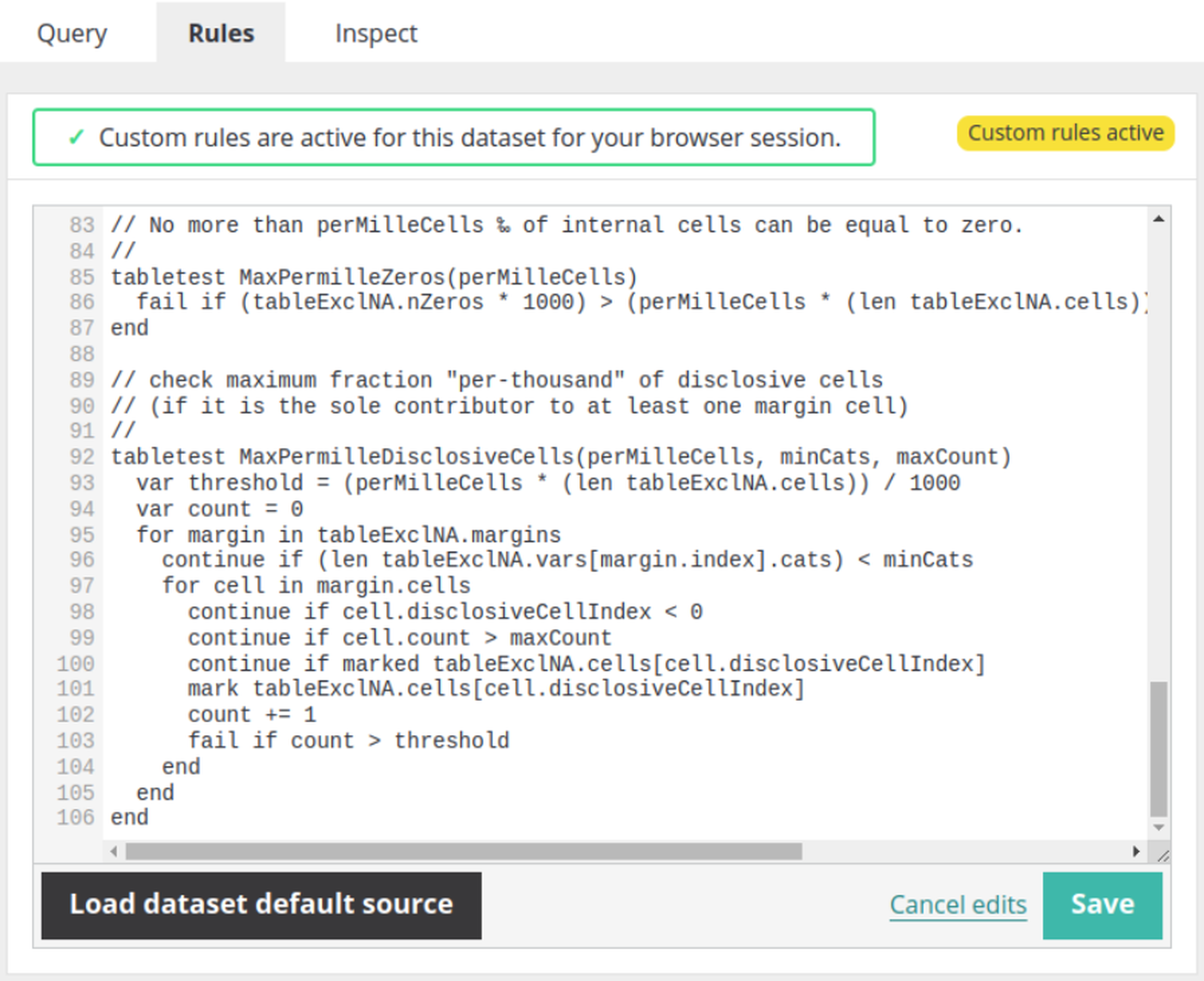
For addressing the automated rule-checks we considered a number of approaches, including integrating with customer supplied code or services. However we settled on what we consider the gold standard: designing and implementing a domain specific language. This gives memory safety while opening the door for continuous performance improvement.
We designed a functional language (i.e. no persistent state) which is easy to understand and describe but also minimalist for the task in hand. The language provides access to only the data that the code needs to make the publication decision. It also prevents many categories of programming errors that are possible in a general purpose programming language.
Pervasive techniques
Cantabular is written in the Go programming language. There are a number of things we can pay attention to that are important for performance:
eliminate bounds checks where possible by leveraging the inference capabilities of the compiler
minimise allocations and re-allocations (i.e. extending slices)
minimise pointers that need to be followed by the garbage collector
avoid copying data if possible
don’t repeat the same computation more than once
Onwards
After the success of our initial prototype, improving the performance of Cantabular has been a long road of continual improvement and discovery. Making fast software is usually like this: it requires both persistence and creativity.
There is always more we can do to improve: we know of further techniques we can use to make it faster, but there is always a trade-off between the performance gained and the time needed to implement the improvement. We are also continuing to enhance the software to add new capabilities such as creating origin-destination outputs which present their own performance challenges.