
Photo by Fotis Fotopoulos on Unsplash.com
5 minute read
Automating disclosure checks with our Disclosure Rules Language
Last week we released a new version of Cantabular with a big new feature: a disclosure rules language.
The disclosure rules language, or DRL, is a tool to help statisticians automate decisions about table publication which they might previously have made using manual analysis techniques.
It does this by letting its users encode their own confidentiality rules in a language designed for this purpose.
It works with our API and user interfaces to automatically check requests for tables built from confidential datasets for disclosure risks such as identity disclosure, attribute disclosure and sparsity.

Statistical disclosure control at speed and scale for the England and Wales Census
The ONS is deep in preparations for the Census next year, and is working to make sure that business, government and wider society get as much value from the next Census as possible. One path to accomplish this is by allowing people to make their own queries of the data gathered in 2021, instead of relying on a smaller set of predetermined tables.
To help do this, we’ve been working with them to automate some of the privacy protections they have designed for Census 2021 outputs, based around our product Cantabular.
Cantabular works by programmatically adding noise, and hence uncertainty, to outputs and screening queries and output tables for disclosure risks, in real-time. The performance of our software means that table protection and production can be automated and used to power flexible dissemination tools or as part of a repeatable statistical production pipeline.
Benefits of a disclosure rules language
In Censuses past, checking of tables before publication involved a manual or semi-manual process of evaluating the disclosivity of tables by checking for unsafe cells.
Each published table had to be checked for its own inherent risks, and evaluated alongside all previously published tables to also understand the cumulative risk. This was a hands-on, time-consuming process, but necessary to ensure confidentiality.
For Census 2021, the ONS’s SDC team decided to explore the possibility of automating these checks, and saving their eyeballs. The DRL we’ve created is one of the results of our collaboration with them on this problem and promises a number of benefits:
Saving time by removing the need for manual or semi-manual processes and freeing up thinking time for gnarlier problems.
Enabling the release of thousands or millions of output tables by collapsing the time taken to check a table to milliseconds.
Allowing the creation of custom rules specifically written to match the structure, content and nuance of a particular dataset.
Giving methodologists autonomy to write automated disclosure checks that don’t involve any changes to the underlying software.
What can you do with a disclosure rules language?
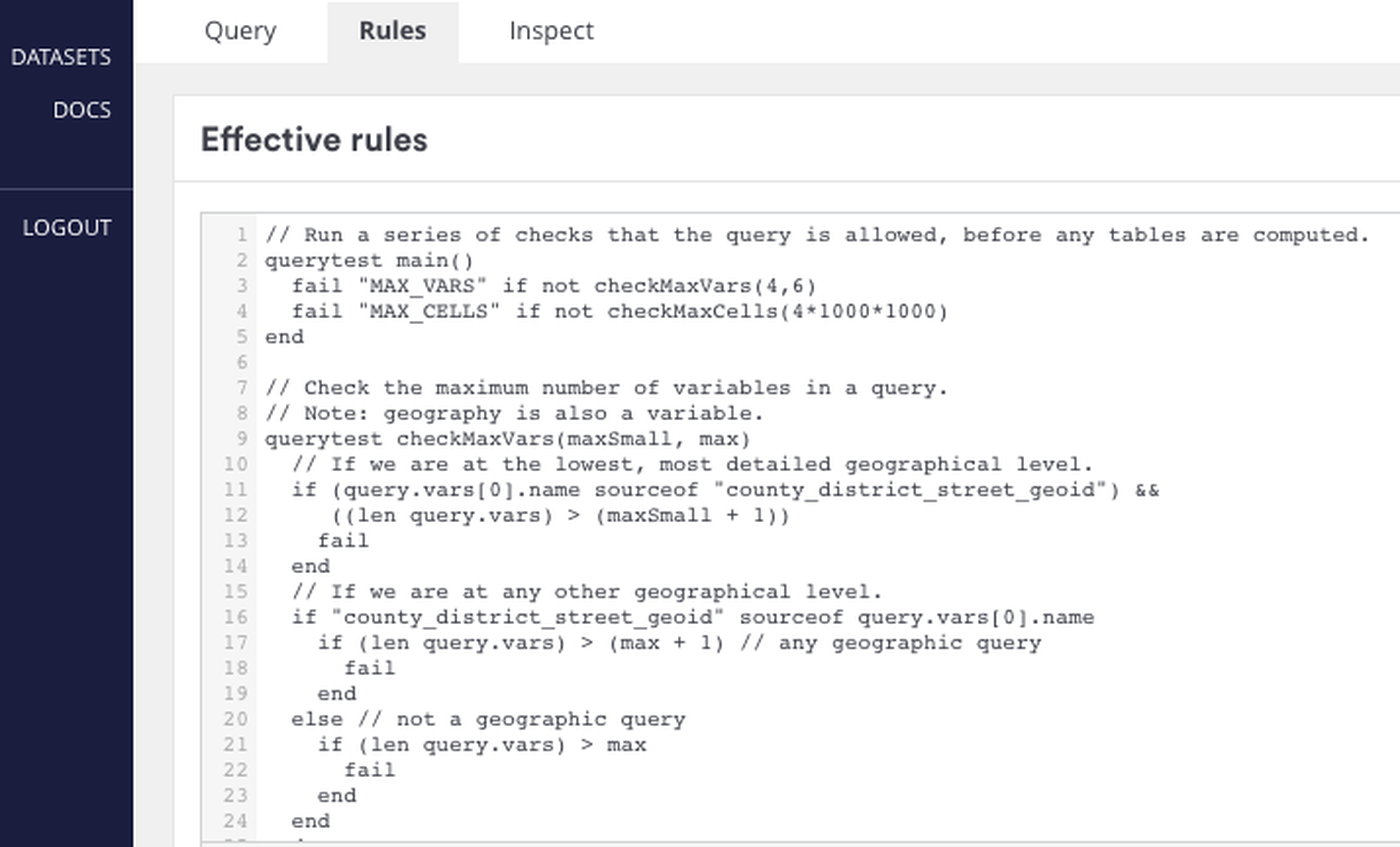
Our new DRL has two elements to it: firstly, it checks that a query received by our API is allowed. Secondly, it checks the disclosivity of the output table produced for each geographic area in the output to evaluate whether it is safe enough to be released.
These elements, and the flexibility inherent in the language to interrogate the properties of an output table, can support a wide range of use cases.
Here are a few of them, largely inspired by a paper published by the ONS’s Statistical Disclosure Control team (Survey Methodology Bulletin 79— Office for National Statistics)
Set maximum variables: block queries that will lead to overly sparse outputs before they’re even run by limiting the number of variables that can be added to a query.
Limit queries for sensitive variables: queries made including particularly sensitive variables could be limited to a smaller number of variables.
Attribute disclosure: individual or group attribute disclosure in a table can be detected and tables with too many instances can be blocked.
Identity disclosure: tables containing too many values of one can also be blocked.
Beyond Census
We’re expecting that the DRL will allow the use of Cantabular for other datasets and by other clients with different needs and in different data domains.
To that end, our language definition is open, to ensure it can be shared, discussed and understood, and to allow anyone to make an implementation. Want to find out more?
If you’d like to find out more about how our product Cantabular works, we’d love to hear from you. Drop us an email at hello@sensiblecode.io.