Internationalisation and right-to-left language support in Cantabular

Photo: Thanos Pal on Unsplash.
A couple of years ago, we added the capability to localise data and user interfaces in Cantabular for different languages.
While our core data service handles data only in a single language, our metadata service supplements this by allowing labels and other reference metadata to be loaded in multiple languages so that all metadata for populations, variables and categories can be translated.
This means both our user interface and API outputs can be made available in multiple languages.
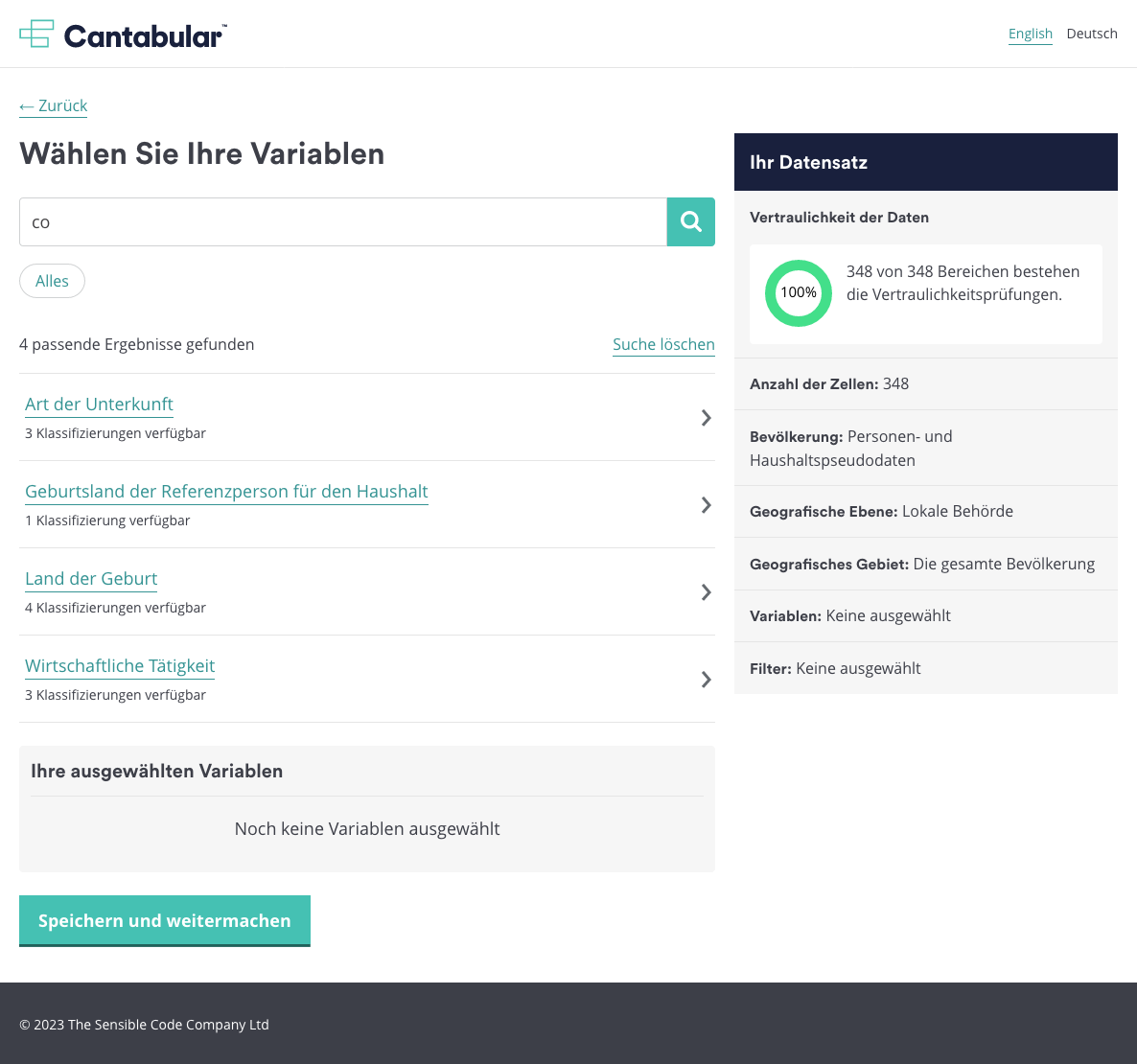
Screenshot: Cantabular’s user interface in German. Translations have been generated automatically so may contain inaccuracies.
We recently took this a step further by making changes to our user interface to add support for right-to-left languages such as Arabic, Hebrew, Farsi or Urdu.
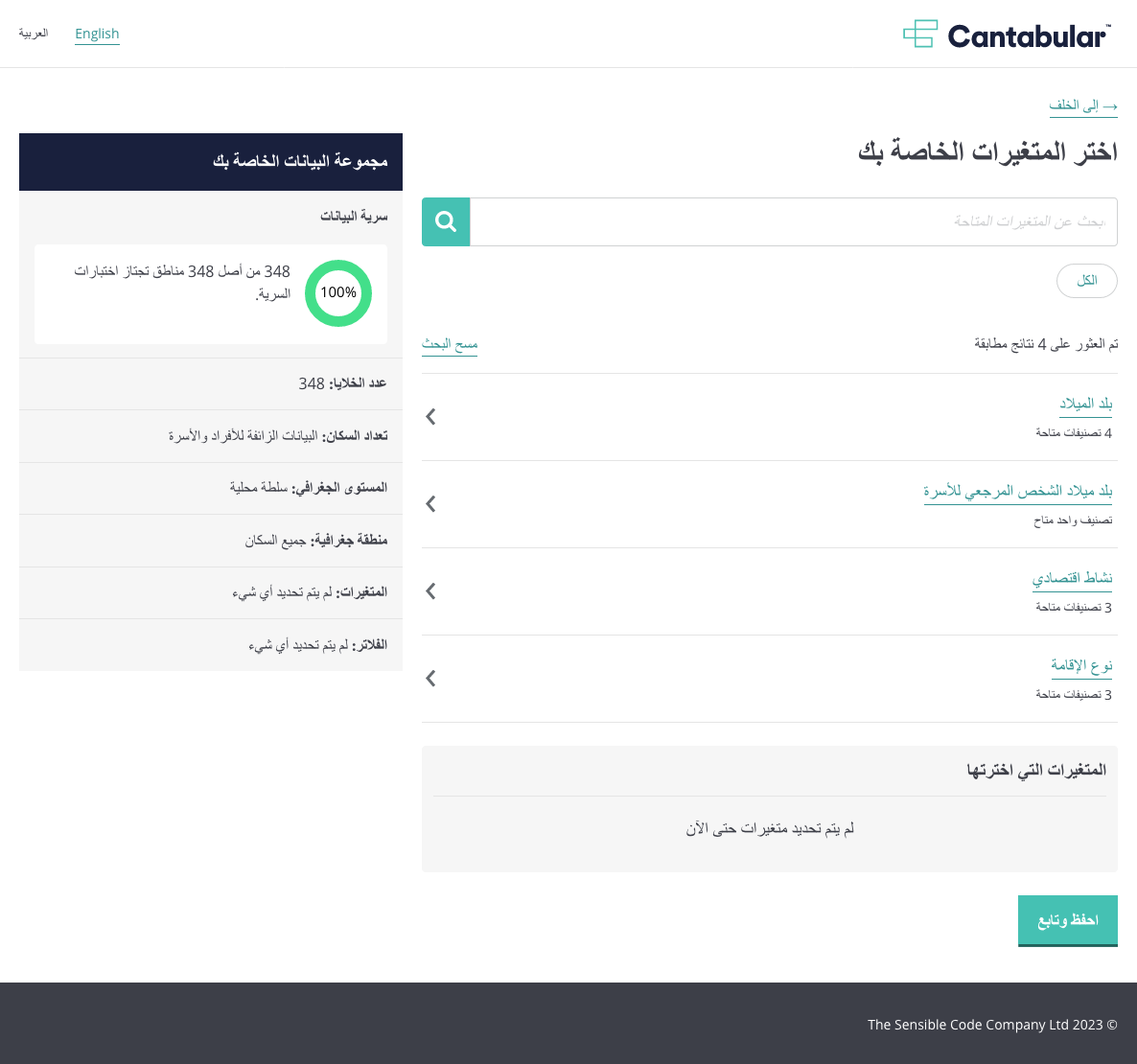
Screenshot: Cantabular’s user interface in Arabic. Translations have been generated automatically so may contain inaccuracies.
This involved making a variety of code changes to:
- automatically identify right-to-left languages when translations are loaded
- audit the layout of all user interface elements and alter where necessary to ensure they flow correctly from right-to-left
- change the way margin, padding and borders are applied to elements to ensure they work for both left-to-right and right-to-left languages
With these small but detailed technical changes, the layout of the interface now flows equally well in both directions, enabling a much more natural browsing and reading experience for speakers of right-to-left languages.
An excellent resource on how to implement right-to-left language support in web applications is the website RTLStyling.com.