Creating a data pipeline for machine-readable metadata

Photo: Erol Ahmed on Unsplash.
This post is part of a series: 2021 England and Wales census publication
- Publishing census data twice as fast with the ONS
- Creating a data pipeline for machine-readable metadata
- Real-time tabulation and perturbation of census results
- Transforming the England & Wales Census with Cantabular
Over the last few years we have worked with the ONS to help automate the production of outputs for the 2021 census. You can read more about our work in Aidan’s blog post.
Thanks to our software Cantabular, the ONS can generate cross-tabulations and apply privacy protections in real-time. However, statistics are only part of the story. Metadata provide crucial information about the numbers, and form an essential part of census outputs. When cross-tabulations are created on demand, or flexibly, metadata that relate to them also need to be put together on demand.
We have developed a flexible metadata service and have been collaborating with the ONS on the creation of a data pipeline for machine-readable metadata. We have come up with a solution that pulls data and metadata into a single source of truth, allowing ONS teams to build innovative, flexible outputs using a single API.
Metadata everywhere
There are many different types of metadata that can be present in a statistical output such as descriptions of variables, related survey questions, and information about methodology, among others. These metadata may come from a variety of different sources and be stored in different formats such as databases, spreadsheets, Word documents, PDFs or online resources.
Traditionally, statistical outputs have been manually compiled. The authors would gather the metadata from various sources, correct any errors, select relevant sections from long documents, and adapt formatting to meet their needs.
However, this approach isn’t suitable for flexibly generated outputs, as metadata must be compiled in an automated, dynamic fashion from machine-readable sources as required.
Cantabular metadata service
This is where Cantabular’s metadata service comes in. It allows for the publication of metadata alongside safe cross-tabulations. Customers have the ability to design a metadata schema that suits their needs, while users of the metadata service can request only the metadata they need via the flexible GraphQL API.
For example, the Cantabular metadata service might be set up to provide a label, description, related survey source question and related keywords for each variable in a cross-tabulation. One user of the metadata service might only be interested in high level information and could construct a GraphQL query that only returned the description for each variable. Another user might be interested in more detailed information so could construct a query that returned all the available metadata.
The Cantabular extended API integrates with the metadata service and our data service, allowing users to request cross-tabulations and supporting metadata via a single GraphQL API.
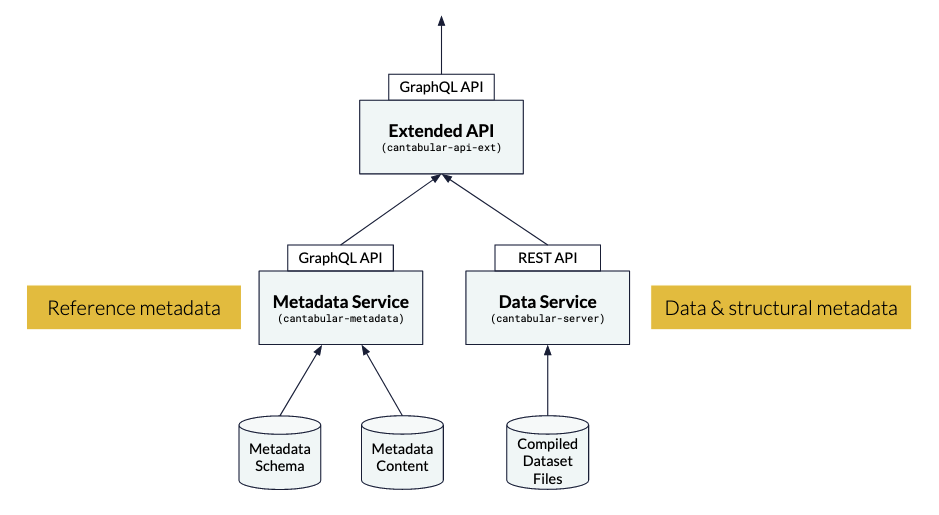
Diagram: How the metadata service integrates with Cantabular’s extended API
In order to load metadata from different sources and file formats into Cantabular, they firstly need to be brought together in a consistent, machine-readable format. We’ve taken a standards-agnostic approach that allows us to both consume and produce metadata in a variety of formats if required, whether that’s CSVW, SDMX or something different.
Metadata for the 2021 census
The generation of metadata at the ONS is a collaborative effort, involving experts in fields such as geography, statistical disclosure control and statistical outputs. As a result there are many different source documents in a variety of formats.
The metadata team at the ONS did a great job consolidating this information into a centralised data repository. They gathered metadata requirements through consultation with the various teams responsible for generating census outputs. Based on these requirements they defined a relational schema which specified the metadata fields which should be available. The metadata were collected from the source documents and stored in their repository.
With the information in one place, it was easy for the ONS team to send metadata to their translation partner to meet the need for bilingual census outputs.
Census metadata in Cantabular
We took the machine-readable metadata created by the ONS and wrote an open source Python script to convert these into the format required for the Cantabular metadata service.
When data are manually authored and assembled it is highly likely that some problems arise. Humans are quite poor at spotting a handful of errors in tens of thousands of data records, but this is something that computers excel at.
We used our software skills to automatically detect inconsistencies and spelling mistakes in these metadata and ensure that all the required information was present. We fed this information back to the ONS team and worked with them to enhance their processes to produce high quality metadata.
By loading the ONS metadata into Cantabular, all necessary metadata were centralised and accessible through a flexible API. Teams could easily describe and explain tables, variables, and populations. They can even switch between languages by changing a single parameter in an API query (although this functionality is not used in the census project). The outputs from this API can be used across a variety of different census outputs—in web applications, visualisations, Microsoft Excel downloads, in data dictionaries—all drawing from the same machine-readable single source of truth.
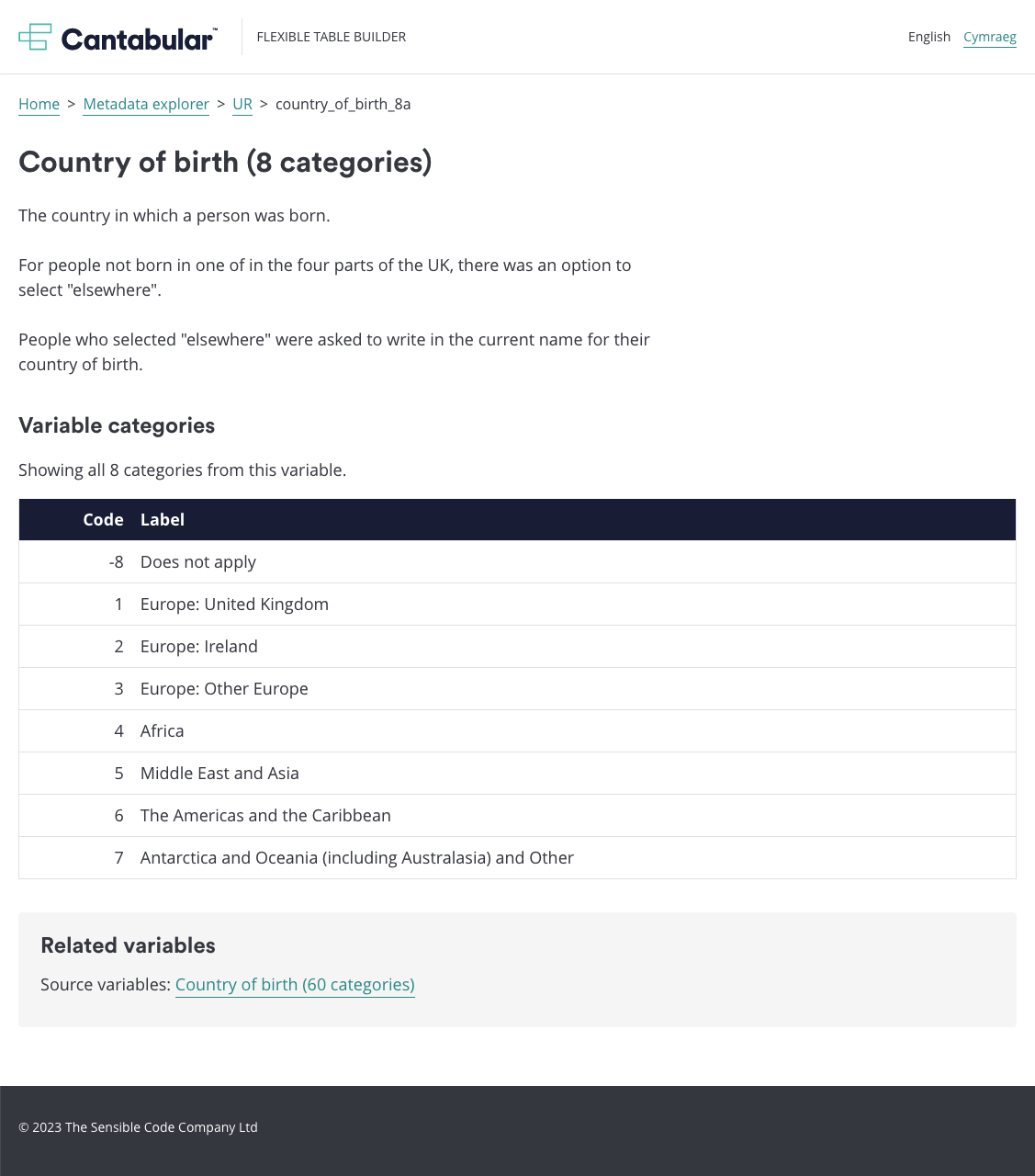
Screenshot: The metadata explorer in Cantabular’s public user interface
Future work
We are currently investigating possible enhancements to our metadata offering. In the near term we’re looking at generating outputs in CSVW format, where information from the Cantabular metadata service will be used to describe the contents and structure of CSV data files
We’re also considering the development of a simple user-friendly metadata authoring and dissemination system. A customer would define a metadata schema, and the platform would automatically generate an input form with appropriate data validation. Metadata could be entered through a user-friendly web-based interface, or uploaded in bulk in a machine readable format. Once complete, the author could publish the metadata and make it available through a flexible API.