Creating an Irish translation of the 1911 Ireland census report

Photo: The Titanic under construction in Belfast, 1911. Robert Welch, Public domain, via Wikimedia Commons.
{kind=link}
In 1913, the release of the 1911 Irish census report was exclusively in English. Today, we are pleased to release our interpretation of how this report might have appeared if it had been originally presented in the Irish language.
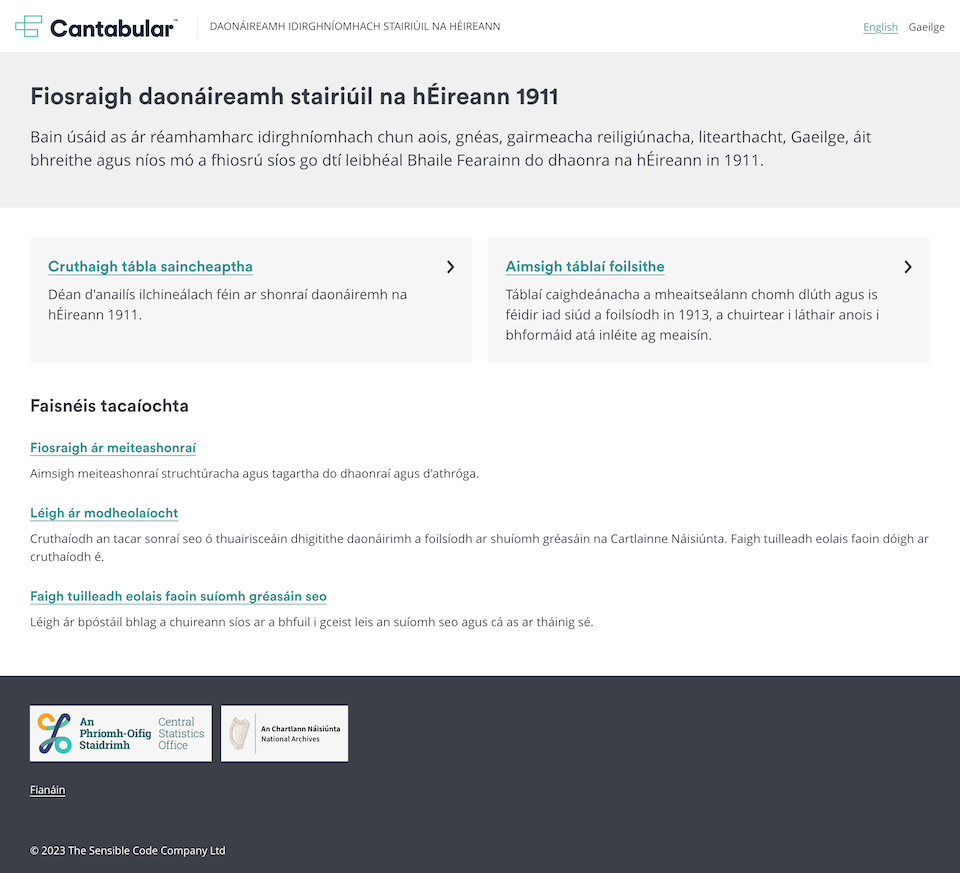
Screenshot: Cantabular and the 1911 Ireland census in Irish
Cantabular has had the capability to support multiple languages for a couple of years built originally to help the ONS manage English and Welsh translations within their census publication data pipeline.
Following on from our work unlocking the value of the 1911 Irish census records, we were keen to use this new capability to add an Irish translation of this historical data.
Challenges with translating historical data
Translating software is a well-established practice, but translating the metadata for a historic resource like this presents its own unique set of challenges.
One challenge relates to geography. For the purposes of this release, we opted to restrict geographical translation to Provinces and Counties, omitting District Electoral Divisions and Townlands because of the sheer volume of data involved.
We are aware of the valuable work done by projects such as Irish Townlands and the Placenames Database of Ireland. Still, at this stage, we decided not to integrate with these projects, although we may revisit this decision if our work proves to be of benefit and as we continue to add features to the software.
Another challenge was the translation of county names. Following the establishment of the Irish State in 1923, the county names of Offaly and Laois were changed from “King’s County” and “Queen’s County.” For our translation, we opted to use the modern names of these counties rather than the original names as they appeared in the 1913 report.
Automating translations with human input
We use an agile methodology for software development, following a structured workflow that involves task planning, test creation, coding, and code review before a new feature is released. Integrating translations into this process without interrupting or delaying our workflow posed a potential challenge.
Our initial idea was to rely solely on automated translation services, as this approach would provide the quickest turnaround. However, it had the drawback of not including a human proofreading step, which raised concerns about translation quality and consistency over time.
At this juncture, we sought advice from Marcas MacCoinnigh of Queen’s University, who suggested a dual approach. We would first employ automated translation and then have the results proofread by a professional translator. Ultimately, this is the approach we adopted.
The process we followed can be summarized as follows:
- We divided all the content requiring translation into two distinct files: static user interface translations and metadata translations for the 1911 Ireland Census.
- These files were then processed through Amazon Translate to automatically produce an initial translation.
- We subsequently shared these translated files with our translator, Daniel McWilliams.
- He then undertook the task of refining the Amazon Translate output.
- This collaborative work was conducted through Google Docs, together with a set of scripts that allow us to automate the integration of the translation review back into our data pipelines.
Having set up this process it will be easy for us to manage additional translations as we add new features to the software and new metadata to the underlying data source. It also gives us a template for how to work with translators on future Cantabular projects.
With the translations completed, both the user interface and the application programming interface (API) for the 1911 Ireland census are now available in Irish, giving a completely new perspective on this historic statistical resource.