Republishing the historic 1911 Irish census as an interactive dataset
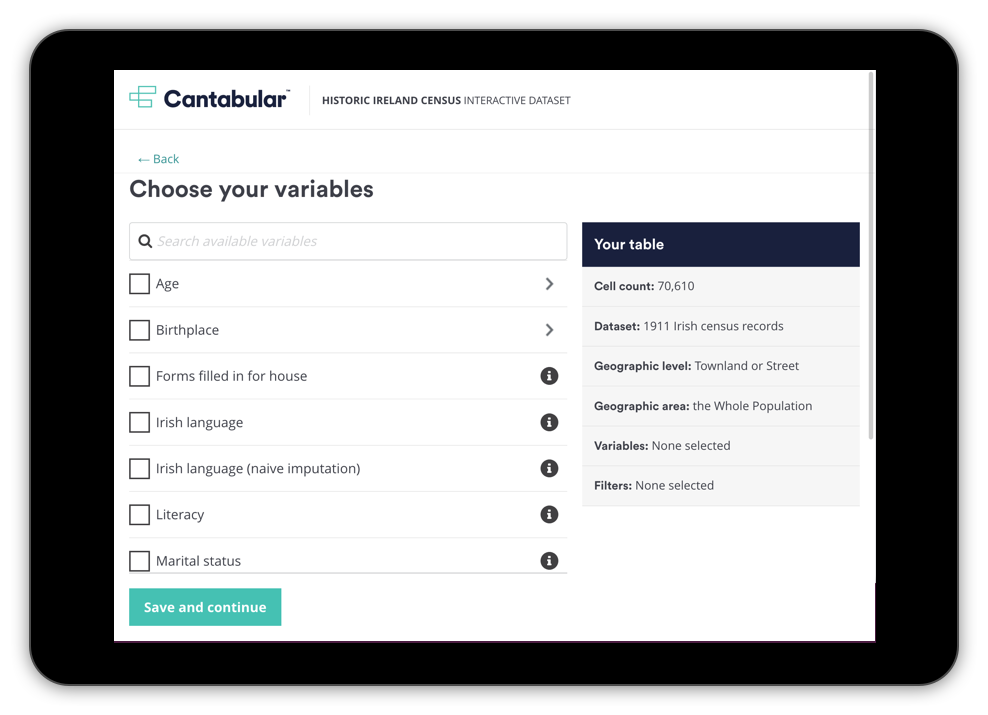
Picture: Our new website to allow people to cross-tabulate 1911 census data
This post is part of a series: 1911 Irish Census
Today we are releasing a new public website that makes the returns from the 1911 Irish census available as a preliminary statistical release to be queried by anyone.
All kinds of cross-tabulations and analysis of this data that were previously impossible are now easily accessible as open data through our user interface and API.
Historic census data can be tricky to find and work with: it sits behind paywalls in the databases of genealogy companies or in strictly controlled environments accessible only to approved academic researchers.
We built this project to exemplify a different approach and to show what is now possible with modern technology, particularly when you’re publishing data without confidentiality constraints.
To find out more about what we’ve done and why, keep reading. If you’re impatient to see it in action, here’s the link again: https://ireland-census-preview.cantabular.com.
Beginnings
A year or two ago, my colleague Aidan moved to Belfast, a move that prompted him to research the history of the partition of the island of Ireland and how decisions were made about the location of the border.
His research led him, via a trip to Ulster University in Derry, to the physical 1911 census reports and onwards to the digitised records held by the National Archives of Ireland. Doing research with the original printed reports or PDFs was tedious and slow and the digitised records didn’t allow cross-tabulations to be created. He realised that we could—fairly easily—scrape the National Archives data, clean it up and publish it using our product Cantabular, recreating the 1911 census reports in a digital form.

Picture: The summary results for County Armagh from the 1911 census. taken from the Province of Ulster report. Source: Internet Archive
Cantabular is a software framework for the protection and dissemination of statistical data that we’ve been developing for the last four years or so. It’s also being used by the Office for National Statistics in the UK to help with the protection and publication of the 2021 England and Wales census.
Data machinations
Of course, data being data, it’s never as easy as you think, and my colleagues Steve, Mattie and Aidan have spent a good chunk of time since then scraping, cleaning and processing the data, as well as checking it against the original reports to get it as close as we can, within a reasonable timeframe, to the counts as published in 1913.
We ran an event at the end of April 2021 for around 150 other census and statistics geeks about our work on all of this which we recorded and published. So you can see Steve’s talk about how we got hold of the data and watch a talk Aidan and I gave about using our user interface and API to explore some of the inconsistencies between the digitised records and the original reports.
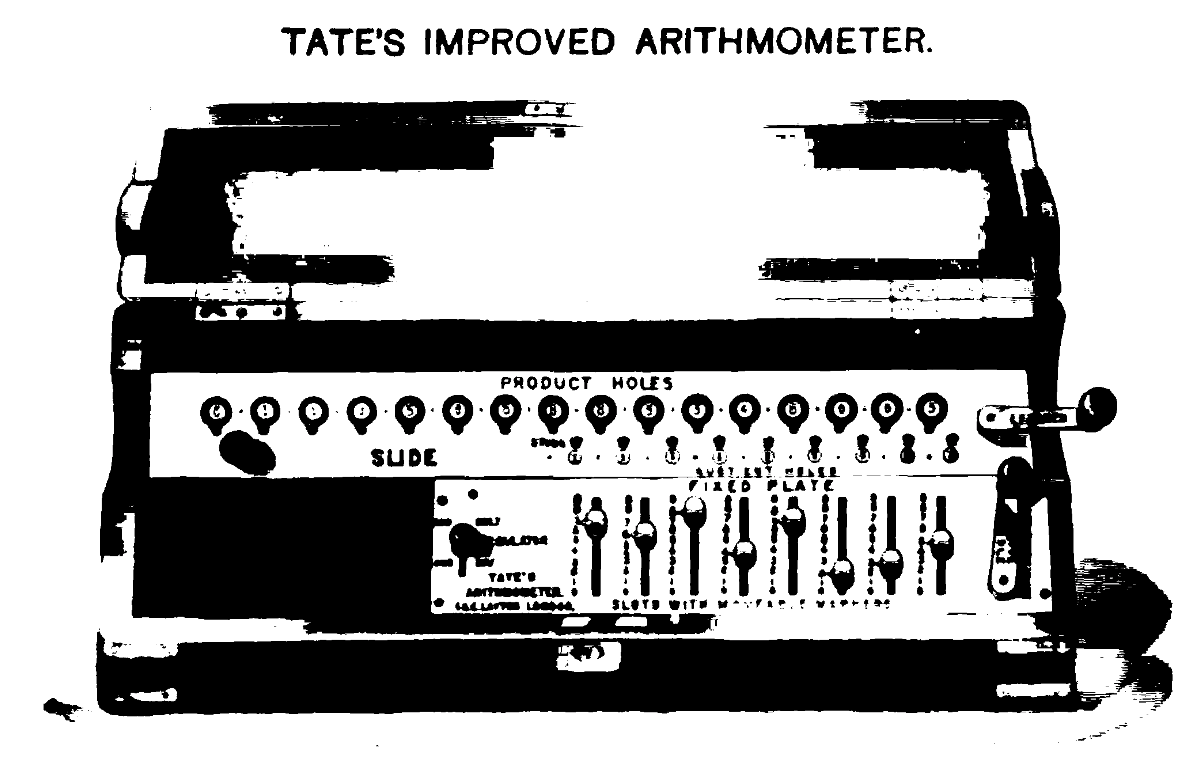
Picture: Tate’s Arithmometer, a calculating machine, as purchased by the General Register Office, Dublin in the late 19th Century. Source: The Mechanism of Statistics, RE Matheson, 1889
110 years is an awfully long time in technology, so while in 1911 they were stuck with folding flaps, arithmometers and 1000s of person-hours of computational labour to do their processing and cross-tabulating (as discussed by our non-executive director Gerry O’Hanlon in his talk), we were able to lean on Python, Pandas and Jupyter to help us move somewhat faster.
Creating cross-tabulations
With the data prepared and loaded into our software, we can now create cross-tabulations on demand that weren’t previously possible. For example, while in 1913 the province reports were limited to cross-tabulations such as province by religion by sex, we can now add more detail at lower geographic levels and try out different combinations. For example we can:
- Create a table of religion by age and by sex for every Townland (mean population of ~60) in Ireland
- Add a filter to show just women over the age of 40
- Change the geographic coverage to just look at Townlands in County Cork
Here’s a video showing you how to do the same thing with our user interface.
Automating access
If accessing data from your own scripts or apps in a machine readable format is more your thing, we also have a GraphQL API to programmatically request the exact same kinds of data you can get through our user interface.
GraphQL might sound obscure if you’re not familiar with it, but it’s actually a very simple query language for asking an API for only the specific data you want using a syntax very similar to JSON (a widely-used format for sharing data) that was dreamed up by the clever folks at Facebook.
Our API, along with an interactive API explorer, is openly available here. To help get you started we’ve put together a few code samples to show how to work with the row-major order counts it produces in response to requests for tables.
The screenshot below shows the GraphQL query and response for a cross-tabulation of the population by religion and by sex for all counties in Ireland.
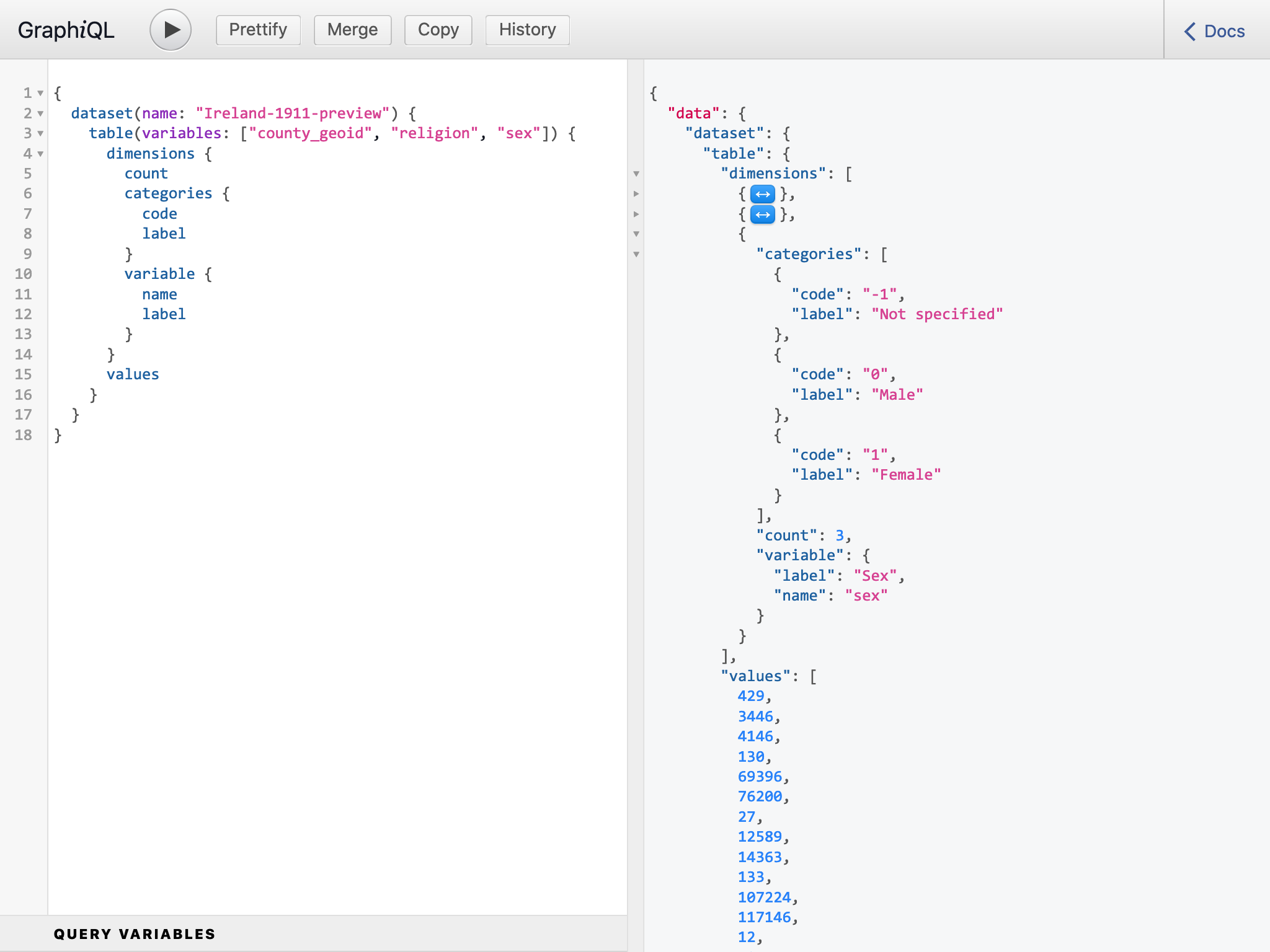
Screenshot: Using GraphiQL to query Cantabular’s API
Maps and charts
Very early on, we decided that we wanted to be able to build on our GraphQL API to allow mapping of the data. While doing this for provinces and counties is trivial, visualising data for the thousands of historic District Electoral Divisions (DEDs) turned out to be a lot harder because the boundary data doesn’t exist in an open format and because of a lack of common identifiers to connect the census and boundary data together.
To help tackle this issue, we worked with the wonderful OpenStreetMap Ireland and one or two dedicated members in particular, to get the remainder of the historic DEDs mapped openly (they’d already done the Townlands!) and loaded into OpenStreetMap so we and others can make use of them. The main protagonist from OSM, Anne-Karoline Distel, also spoke at our event to describe how she had tackled the problem.
Shown below is the output of an Observable notebook we’ve created that uses these OSM boundaries and fetches data from our API to allow flexible creation of choropleth maps for a number of different variables in the dataset. It’s a live demo, so try it out!
All visualisations are available for use under a Creative Commons Attribution only licence.
The potential of historic censuses
Going through this process has given us a totally new perspective on the value of historic censuses. While outputs from recent censuses have been fairly comprehensively published, historic census data is typically hard to find and to work with. It’s often accessible only through two limited means: via genealogy companies as a resource for individual research by members of the public and via data archives as a tightly controlled resource for academic researchers.
The opportunity we saw here, and we hope we’ve managed to realise it, was to demonstrate a simple but powerful approach to statistical dissemination: a public, open data release of a custom query tool.
We hope it will be of value to the public and researchers alike and exemplify a new approach to the exploration of the social character and demography of the past.